 Photo by Frantisek Duris Unsplash
Photo by Frantisek Duris Unsplash
Table of Contents
Open Table of Contents
Introduction to GraphQL
What is GraphQL
GraphQL is data manipulation and a query language that enables declarative data fetching. From a different viewpoint, GraphQL is Facebook’s solution to having a smart endpoint that receives queries and mutations rather than having lots of dump endpoints and giving data according to clients’ requests and needs.
GraphQL is transport layer agnostic so it can be implemented in any network protocol like TCP, HTTP, Websockets…
Why to Use GraphQL
The most important feature of GraphQL is clients can fetch data according to their needs, therefore the problem of redundant or inefficient data fetch is eliminated. (This is good for mobile applications where mobile data is limited.)
What are the types of redundant or inefficient data fetch?
- Over Fetching: It’s about the server giving more information to the client than requested.
- Under Fetching: It means generally server provides less information than requested so the client needs to execute multiple queries.
Both types result in redundant network usage.
Which Situations Should I Use GraphQL
- If your API is used by multiple clients including network-restricted clients(mobile devices, IoT, smart watches, etc.)
- If your API is getting more and more complex and unmanageable (i.e. you have hundreds of endpoints/queries)
- For applying composite pattern putting GraphQL endpoint to the front of multiple microservices.
- For retrieving nested data. For example, retrieving a set of blog posts and inside each post retrieving that post’s description.
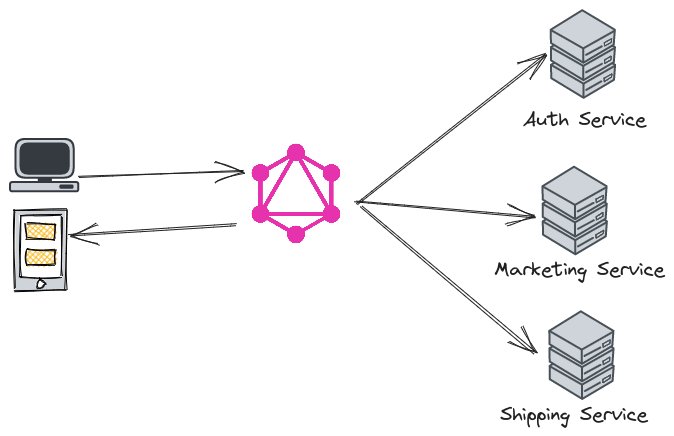 Using GraphQL as a Composite
Using GraphQL as a Composite
REST vs GraphQL: What are the differences?

What is the equivalent of CRUD in GraphQL?
- Create: Mutation
- Read: Query
- Update: Mutation
- Delete: Mutation
In which situations should I use REST over GraphQL?
- If you want robust API with monitoring and caching.
- If your API is not so complex and consists of simple endpoints.
So which is the best? Tired of hearing but there is no silver bullet so you should select either according to your needs. Buy pay attention to GraphQL may be overkill.
Building Blocks of GraphQL
 Photo by Susan Holt Simpson Unsplash
Photo by Susan Holt Simpson Unsplash
How GraphQL works in the simplest way?
You have a single endpoint (e.g. http://localhost:4000/graphql) and the
client sends a serialized request (JSON, XML, TEXT) that obeying to GraphQL
schema for altering ( with a mutation) or querying ( with a query) data.
GraphQL Schema
GraphQL schema defines how data is looking like. Schema specifies rules for altering or querying data. For example how a client should fetch or mutate data.
GraphQL schema is written using schema definition language. (SDL)
For example:
type Comment {
author: String!
content: String!
}
type Post {
id: ID!
title: String!
content: String!
comments: [Comment]
}
type Query {
posts: [Post]!
postsWithTitle(title: String!): [Post]!
}
type Mutation {
createPost(title: String!, content: String!): Person!
}Note: Exclamation marks indicate the field is required.
Explanation of schema:
- We have some type of Post that includes an array of comments in the property
commentsand comments are not required. - We have two queries to fetch posts, one for all posts and one for posts that are filtered by the title that returns an array (can return empty array but cannot return null)
- We have a single method for altering/mutation posts and it is the creation of posts with required arguments of title and content.
What are the basic types in GraphQL Schema?
The basic types in GraphQL schema are called GraphQL Scalars Types (essentially they represent the leaves of the query, further information: Scalar Types)
- Int: Signed 32-bit integer.
- Float: Signed double-precision floating-point number.
- String: A UTF-8 character sequence.
- Boolean: True or false.
- ID: An unique identifier, serialized the same way as String.
Due to the strong type system that GraphQL schema provides frontend and backend teams easily work independently.
Schema Stitching
With schema stitching, you can take two or more GraphQL schemas and merge them into one endpoint. This endpoint can pull data from all of them. This endpoint delegates the client request to subschemas that is responsible for providing requested fields.
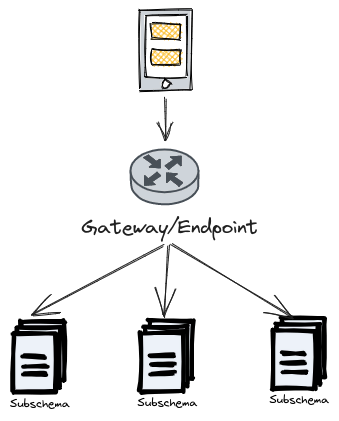
For further information: Understanding Schema Stitching
Fragments in GraphQL Schema
A GraphQL fragment is a piece of logic that can be shared between multiple queries and mutations.
fragment NameParts on Person {
firstName
lastName
}so we can use it later in query or mutation…
query GetPerson {
people(id: "7") {
...NameParts
avatar(size: LARGE)
}
}and it is translated to …
query GetPerson {
people(id: "7") {
firstName
lastName
avatar(size: LARGE)
}
}Taken from: Apollo Docs — Fragments
Anatomy of GraphQL Queries
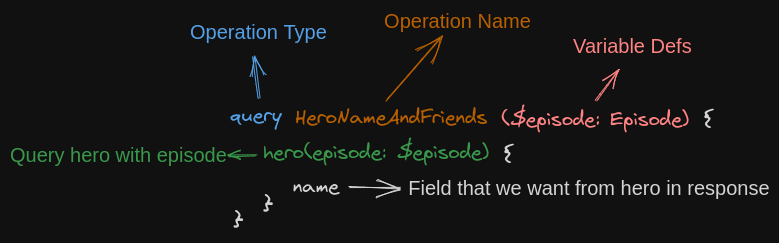
Queries
Queries are used for querying data (i.e. GET request)
Example query of client:
query {
serverCounter {
amount
}
}Explanation: We are querying the amount of serverCounter. After this request server will provide the field amount from serverCounter if the operation succeeds.
How it looks like in the server’s schema: (SDL):
type Query {
...
"""
This is comment string.
Below line is called `field`
"""
serverCounter: Counter
...
}Example response:
{
"serverCounter":{
"amount": 35
}
}Example query with parameters:
query {
post(id: "507f191e810c19729de860ea") {
title
description {
author
}
}
}How it looks like in the server’s schema:
type Query {
...
post(id: ID!): Post
...
}Example response of server:
{
"post": {
"title": "Some title",
"description": {
"author": "Graphly Resty"
}
}
}Mutations
Mutations are used for altering data(updating, creating, deleting, etc.)
Example mutation:
mutation{
addPost(input: {title: “post3”, content:”new post”}){
id
title
content
}
}Exp: We are creating(according to mutation name) a post with parameters title and content. We tell to the server that we want to receive title, id, and content as a response.
How it looks like in the server’s schema:
type Post {
id: ID!
title: String!
content: String!
}
type AddPostInputType {
title: String!
content: String!
}
type Mutation {
…
addPost(input: AddPostInputType!): Post
…
}Example server response:
{
"addPost": {
"id": "5271a0ca-0dc4–11ee-be56–0242ac120002",
"title": "post32",
"content": "new post"
}
}Subscriptions
Subscriptions are query type that subscribes to data for changes. It’s used for tracking real-time updates to data. Stream of data used in subscriptions rather than request/response. Generally uses WebSockets under the hood.
Example subscription:
subscription {
counterUpdated {
amount
}
}Exp: We are subscribing to the event counterUpdated. When the amount changes server sends it to the client.
How it looks like in the server’s schema:
type Counter {
…
amount: Int!
…
}
type Subscription {
…
counterUpdated: Counter
…
}Example response of server:
“counterUpdated”:{
“amount”: 25
}Note: We should omit parentheses from the field’s declaration if the field does not take any arguments.
Resolvers
Resolvers are responsible for producing data for all fields in the schema. A
resolver provides data for a single field. (some example fields from above:
Subscription.counterUpdated, Query.post, Mutation.addPost)
Resolver functions take four arguments according to the standard:
- root: Result from parent resolver, used for transferring data from parent resolver to child resolver.
- args: Arguments provided in client request for the field.
- context: Created for every request. It is a mutable object shared among all resolvers. Context is a good place put some common data like authorization status etc.
- info: Specific to the field. It is information about the operation’s execution state and the path to the field from the root. (See: GraphQL.JS)
Doesn’t it seem like a waste to have Resolver functions for each field?
Yes, we need to define a resolver for each field but in practice, this is not the case thanks to GraphQL default resolvers.
A default resolver will look in root to find a property with the same name as the field.
The above quote is taken from the article GraphQL Resolvers Best Practices you can take a look at it if you want to deep dive to resolvers.
Show Me an Example
 Photo by Tolga Ulkan Unsplash
Photo by Tolga Ulkan Unsplash
What are the requirements?
Client, Server, Schema, and Resolver.
How client sends the query?
async function fetchPost() {
const response = await fetch("http://localhost:4000", {
method: 'POST', // GraphQL queries are POST.
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
query: `
query {
posts {
id
title
}
}
`,
}),
});
console.log(await response.json());
}So what about the server…
const { ApolloServer, gql } = require('apollo-server');
// We are defining schema using SDL in here
const typeDefs = gql`
type Post {
id: ID!
title: String!
content: String!
}
type Query {
posts: Post
}
`;
// Resolvsers for the fields
const resolvers = {
Query: {
posts: () => ({id: "some-id", title: "Some title",
content: "Some content"}),
},
};
// Init server
const server = new ApolloServer({ typeDefs, resolvers });
server
.listen({ port: 4000});The Complex Example
Some Questions to Answer
Should we parse the query?
No. Third-party tools parse automatically queries in general. We are responsible for defining the schema and writing resolvers.
What happens if parsing fails? Syntax Error.
Can I use GraphQL without using any library?
Yes because it is standard.
Why all GraphQL queries are POST?
It is not required, it is convention. We can use GET but it is unusual to send a request body on GET and we should send query data as the body.
Code First vs. Schema First
- Code First: This Means firstly writing code and generating schema from code automatically. ( For example TypeGraphQL)
- Schema or SDL First: This Means writing schema first and generating code automatically. (For example graphql-codegen)
Which is the best?
Both have advantages and disadvantages over each other. I personally prefer the code-first approach but you can invest further in this and this resource
Which languages can I use GraphQL?
GraphQL is a standard you can use in any language.
Some Useful Tools to Notice
Awesome GraphQL
Awesome list of GraphQL.
GraphiQL
In the browser GraphiQL like Postman.
GraphQL Playground
GraphiQL integrated with Electron.
Dataloader
Javascript library developed by Facebook is used for data caching and batching.
VulcanJS
Full-stack React-GraphQL framework.
Apollo Client
GraphQL client for every UI framework.
Relay
GraphQL client developed by Facebook.
Apollo Server
GraphQL server compatible with the standard.
GraphQL-Http
Zero dependency javascript server library.
GraphQL-Dotnet
GraphQL for .NET.
Gatsby
React static site generator powered with GraphQL.
GraphQL Voyager
Visualize your GraphQL.
Prisma
Next-generation ORM with first-class support GraphQL.
TypeGraphQL
Code-first tool for typescript.
Conclusion
GraphQL is a standard developed by Meta for easily maintaining complex APIs. It defines a protocol called Schema which defines communication rules between client and server. The basic types in the schema are called scalars. In GraphQL we can query data with Queries and alter data with Mutations. It also supports real-time updates on data with Subscriptions. Every query, mutation, and data type is defined in GraphQL schema so we can say GraphQL has a strong type system. Resolvers handle requests that come from the client. GraphQL should be preferred over REST for network-restricted environments and APIs that have a hundred endpoints.
Thanks for reading…